
Cyber-Fauci: Deep Reinforcement Learning to Optimize COVID-19 Public Health Policy
In this article, we formulate COVID-19 policy-making as an optimal control problem in which we want as few people to become infected with the virus as possible, while allowing people to see one another when it is safe. We then show that recent advances in reinforcement learning can be leveraged to make government social distancing policies that maximize interactions and minimize infections in a simulated population.
Recent advances in artificial intelligence have allowed artificial agents to achieve superhuman performance in games requiring advanced inference and decision-making processes such as Go and Starcraft II. These advancements, driven by research from Google Deepmind, have come from the field of deep reinforcement learning. Reinforcement learning (RL) is a nascent field derived from the combination of the study of reward-based learning in neuroscience with theories of optimal control research in computer science. In the RL framework, agents interact with their environments, learning behaviors that maximize their intake of rewards from the environment by trial and error. Deep reinforcement learning uses deep neural networks to optimize this behavior.
More recent work has brought artificial intelligence to the realm of public policy, finding that reinforcement learning agents can optimize tax policy far better than existing standards . Through the equivalent of thousands of years of experience, RL agents can learn to balance potentially competing objectives, like equity and productivity or economic reopening and public health. To apply these methods to COVID-19 control, we train agents with a reward in the following form:

where a, b, c, and d are positive constants.
Here, it is critical to note that AI applications to any problem will only have the morality that its engineers endow it with. Racial bias in facial recognition systems has become an acute problem. And in the case of training an AI to control epidemics, it is important to note that COVID-19 has disproportionately hurt indigenous communities and communities of color. While the current model does not take into account race or socioeconomic status in its decision-making, any such model to be deployed in the real world should. Similarly, the choice of these positive constants is highly nontrivial; there is no way to objectively measure how many social or economic interactions a society should weigh as equal to one illness or death. This must be subject to individual and collective debate.
Returning to technical implementation, our model attempts to faithfully portray the difficulty that policymakers face by hiding the true number of infections from the policy-making agent. Instead, agents must test a limited number of individuals in the population and take actions based on this testing data. Conversely, the agents are rewarded and trained according to the true number of infections. This kind of task is formally called “partially observable”.
Agents successfully learn to control epidemics according to the given reward function (Figure 1). In Figure 2, we show how one agent adapts social distancing policy decisions within a single epidemic. In Figure 3, we show basic results on the effect of increased testing on optimization. Last, in Figure 4, we demonstrate how altering the reward function leads to different training outcomes.

Figure 1a:
Agents learn to optimize behavior to maximize reward over the course of 500 trials of training.

Figure 1b:
Agents learn how to “flatten the curve”. A sample timecourse of the number of infected individuals is plotted, with a color gradient of blue to red from earlier to later on in training. By the end of training, agents learn to adapt policies to prevent sharp spikes in infections early in the epidemic.
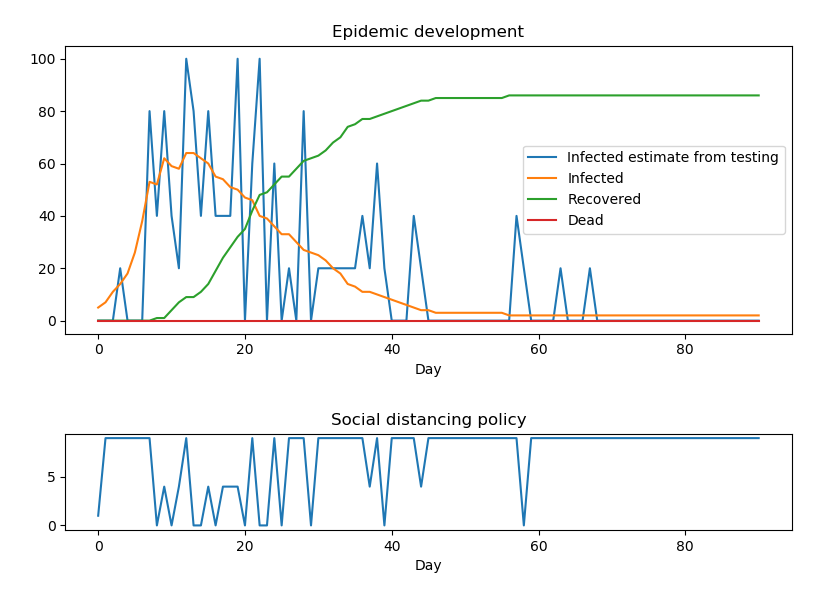
Figure 2: Trained agent behavior on a single epidemic. Agent employs harsh social distancing in the height of the epidemic from days 5-30, and then intermittent control later in accordance with testing results.

Figure 3: Increased testing increases agent efficacy but seems to asymptote at around 5% of the population per day. a) 20 tests per 2000 people per day, b) 100 tests per 2000 people per day, c) 500 tests per 2000 people per day

Figure 4: Modifying the reward function to increase the positive value of increased social interactions leads to less aggressive social distancing policy implementation. a) Reward per interaction: 0.1 b) Reward per interaction: 0.5
This article reports the work of Harvard College Data Analytics Group’s Summer Think Tank. Our Healthcare team, who authored this article, focused on researching healthcare-related aspects of COVID-19.
Access the GitHub repository here.
Edited by Kelsey Wu.